The code tests the Zipstore in the following libraries: zarr-python, xarray, netcdf4, gdal, h5py, and fsspec.
I started by testing the Zipstore with the zarr library. As seen in the output, 
the code is able to open the Zipstore file in read mode with the zarr library with no issues. This shows that the zarr library supports reading and writing data in a Zipstore.
Next, I tested the Zipstore with the xarray library. Xarray is able to open the Zipstore file with the xarray library and read its data. This means that xarray can be used to read and write data in a Zipstore.
The netcdf4 library does not have direct support for reading and writing data in a Zipstore. As seen in the output, the netcdf4 library is unable to open the Zipstore file with the provided code.
The gdal library is able to open and read the dataset.
The h5py library is unable to open the Zipstore file as it is not a valid HDF5 file. This means that h5py cannot be used to read or write data in a Zipstore.
Finally, I tested the Zipstore with the fsspec library. Fsspec is able to open the Zipstore file. Fsspec can be used to read and write data in a Zipstore.
In conclusion, the results show that the zarr and xarray libraries have full support for reading and writing data in a Zipstore. The gdal and fsspec libraries are able to open and read data in a Zipstore. The netcdf4 and h5py libraries do not have full support for Zipstores.
This script is a simple Python program that loads the MNIST dataset, which consists of 60,000 28x28 grayscale images of handwritten digits along with their corresponding labels and saves it in a compressed format using the Zarr library.
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
assert train_images.shape == (60000, 28, 28)
assert train_labels.shape == (60000,)
assert test_images.shape == (10000, 28, 28)
assert test_labels.shape == (10000,)
# write to zipstore
store = zarr.ZipStore("data.zip", mode="w")
z = zarr.zeros(train_images.shape, store=store)
z[:] = train_images
store.close()
The script then uses TensorFlow’s keras.datasets module to load the MNIST data into numpy arrays and asserts the shape of the arrays to verify that the data was loaded correctly. Finally, the script creates a ZipStore using the Zarr library and saves the training images to the store by creating a Zarr array and assigning the images to it. The compressed dataset is saved to the disk and then the store is closed.
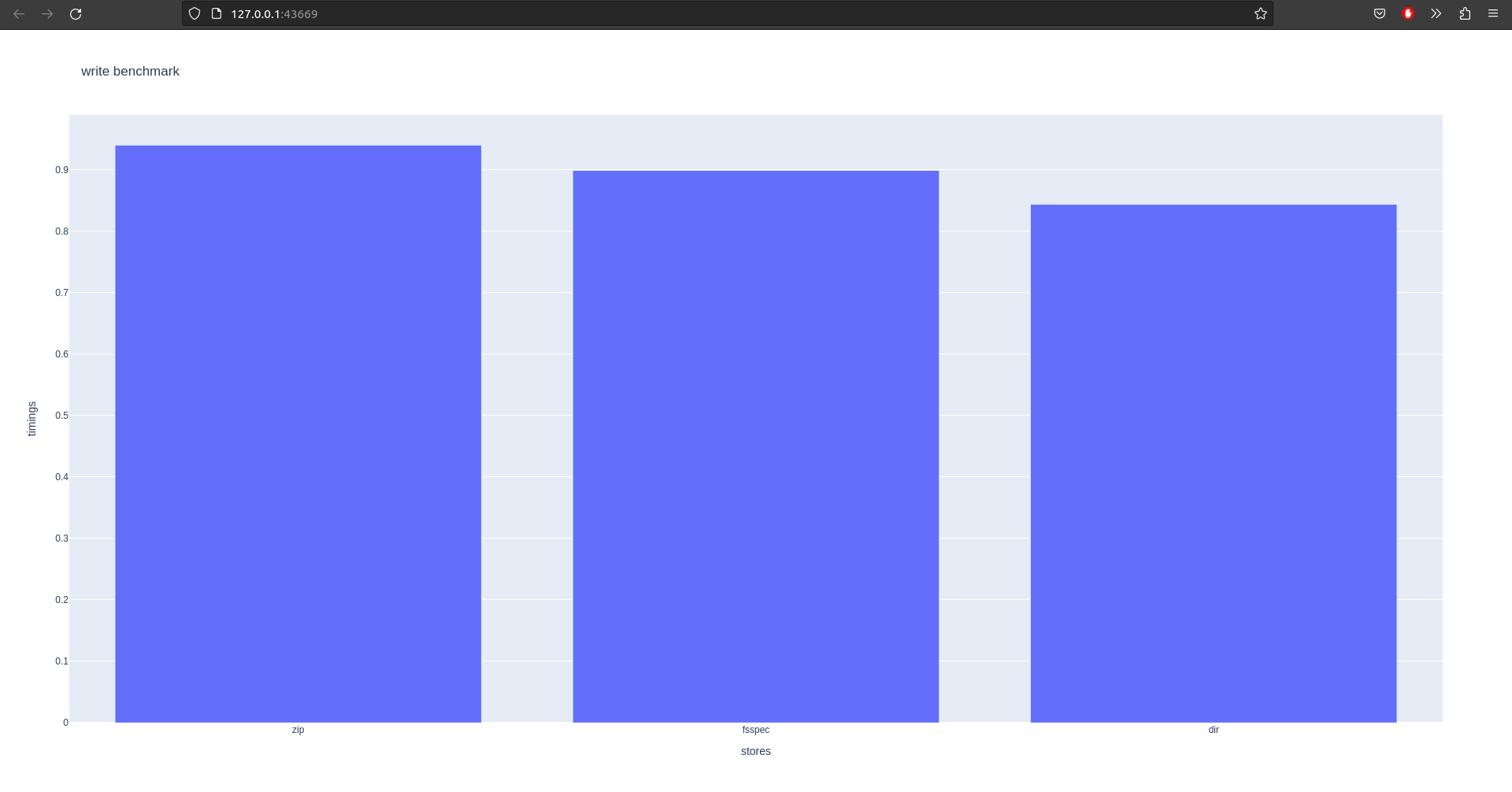
This script shows how I created zarr arrays, checked their integrity and measured the read and write times for different stores. The benchmark class initializes a set of arrays with random integers. The run method takes the store to be benchmarked as an input and performs the write and read operations. The write operation stores the original array in the specified store and the read operation retrieves the array from the store, computes its checksum using SHA256 and compares it to the original array’s checksum.
The stores being benchmarked are the following:
- ZipStore, where the data is compressed and stored in a zip file.
- Fsspec store, where the data is stored in an in-memory file system.
- Directory store, where the data is stored as individual files in a directory.
The results of the benchmark are displayed as bar charts using plotly. The bar charts show the time taken to write to and read from the stores. The results demonstrate that the write time for the fsspec is faster than that of the zipstore and the directory store. The read time for the fsspec and the zipstore is similarly fast but the directory store takes longer to read from.
In conclusion, the benchmark shows that zarr arrays can be stored and retrieved efficiently from different stores. The choice of store depends on the use case and the trade-off between write speed and read speed. For example, the fsspec is fast for read and write operations but the data is lost when the program terminates. The zipstore and the directory store are slower for write operations but the data is persistent and can be accessed across sessions. Fsspec array storage limits us to the size of the memory (RAM) available to us while directory storage doesn’t have this limitation.